









There are a lot more demand forecasts being made today at companies then their used to be – not just monthly, but forecasts that can occur can cover likely shipments for the next day up to a time period that may be for a decision that needs to be made years from now. Many of these forecasts depend upon having more data. Traditionally, demand management applications used order shipment history to make forecasts. But gradually new data sets were added that improved the forecasting accuracy. A demand management application can truly be a Big Data solution today.
The ROI from demand management solutions comes from requiring less inventory to hit a targeted service level. According to Toby Brzoznowski, the Chief Strategy Officer at LLamasoft, a rough rule of thumb is that 1% forecast improvement leads to a 2.5% reduction in the amount of inventory that needs to be held.
The first expansion in the data set was based on getting collaborative data into the forecasting engines. A few years after demand management applications emerged, it was recognized that sales people and marketing people had critical data that could help improve the demand forecast. Sales people might know that a big order was about to drop. The marketing folks knew when promotions would run. Forecasters really needed to know these things. So, tools were devised that helped automate the process of getting inputs from other departments in the company.
When companies are at the beginning of their journey their forecasts are not based on granular data. A company might start by working with aggregate data on how many products, at the regional and product family level, are apt to be sold in a given period. Then a supply chain manager uses splitting formulas to disaggregate the forecast. For example, 80,000 cases of cola that will be sold in the Northeast, let us assume based on history, that 40,000 cases will be regular, 30,000 cases will be Diet, and 10,000 will be cherry flavored.
The next stage would be to forecast at the SKU level at the distribution center level. This is a bottom up forecast where historical SKU shipment data from each DC is used for replenishment planning.
Even more data is needed to plan at the “ship to” level. Here instead of forecasting how much of a SKU will ship in total from a DC, a company is using historical data to forecast how much of a SKU will ship from that DC to every store location in that region that is supported by the DC.
Each stage requires roughly an order of magnitude more data. But by the next stage – the use of point of sale (POS) data for demand sensing – we are getting into Big Data territory. Here, for example, a company might download all the consumption data on which of the company’s SKUs have been sold in the last week or even the preceding day by a given store. Demand sensing requires demand signal repositories to clean, massage, and stage this data.
Solvoyo explained to me at a recent briefing, libraries are needed for event data. This is particularly true when companies get to the demand sensing stage of forecasting maturity. I talked to one Big Box retailer that saw unexpected surges in sales at certain times of the year at certain stores. When they dug deeper, they discovered that they had stores located close to colleges. When the students go back to school after the summer break, the sales surged, but only for certain products. Solvoyo explained that their event library allows these event calendars to be stored and updated so that events can be incorporated into future forecasts.
The data revolution is continuing! In 2017 LLamasoft introduced Demand Guru. Demand Guru has access to over 550,000 data sets across all countries. Many of these data sets are industry and macroeconomic data. The LLamasoft library also has weather data for over 33,000 cities.
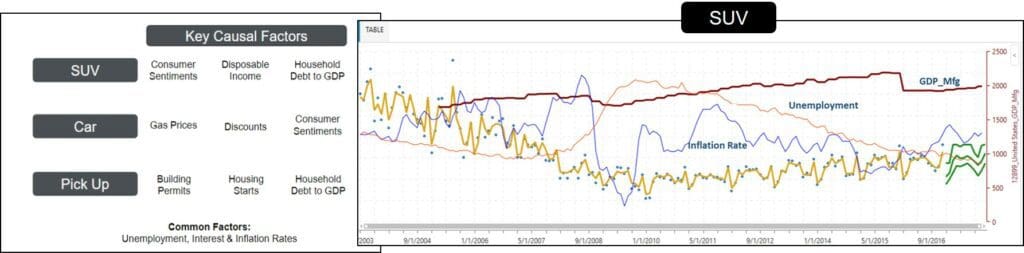
One Automotive OEM uses this solution to improve their 5 to 10 strategic planning forecasts of how many SUVs, sedans, and trucks they will need to produce in regions around the world. In the following figure you can see that many of the key factors improving forecast accuracy for this OEM are based on economic data sets that come out of the LLamasoft library. Macroeconomic factors and machine learning dropped the entire industry level forecast error rate significantly. Just as with demand sensing, using this economic data requires a tool to clean and stage this Big Data set. LLamasoft has also built that tool.
For both demand sensing and the use of economic data sets, machine learning is necessary to sort through the myriad factors causing demand to grow or shrink and to zero in on the drivers that really matter.
More recently, demand forecasters have begun looking at using weather and sentiment data. Sentiment data is based on the positive or negative things consumers are saying about products or companies on social media. There are vendors that provide tools to take this unstructured sentiment data and score it. The process of scoring the data turns it into the kind of structured data that a forecasting engine can use. That data can then be ingested into a demand management system. The use of sentiment and weather data is still at a preliminary stage in the industry. The general thinking is that these data sets will somewhat improve short term forecasts.
In conclusion, in the 20-year journey to improve demand forecasting that I have witnessed, the two most impactful data sets that I have seen are demand sensing (POS) and economic time series data. Both data sets significantly improve forecast accuracy. Demand sensing improves forecasts more in the short-term forecasting horizon. Economic and industry data has a bigger impact on longer term forecasts. Unfortunately, very few companies are at a level of maturity where they are using either.