







Machine learning has been successfully applied to demand planning. Leading suppliers of supply chain planning (SCP) are beginning to work on using machine learning to improve supply (production) planning. But architecturally and culturally, applying machine learning in supply planning is tough.
In the $2 billion plus supply chain planning market, ARC Advisory Group’s latest market study shows production planning as being a critical application SCP solution representing over 25 percent of the total market. Production planning applications are used for both planning daily production at a factory to creating weekly or monthly plans to divvy up the production tasks that need to be accomplished across multiple factories.
Machine learning is a form of continuous improvement. So, in demand planning the machine learning engine looks at the forecast accuracy from the model, and asks itself if the model was changed in some way, would the forecast be improved. Forecasts are improved in an iterative, ongoing manner.
For supply side planning there are key parameters that greatly affect the scheduling. For example, lead times are critical. The longer the lead time, or the greater the variability associated with an average lead time from a supplier, the more inventory a company must keep. But humans are not very good at detecting when these parameters need to be changed and without ongoing vigilance a planning engines outputs deteriorate. The loop between planning and execution needs to be closed to prevent this.
Cyrus Hadavi, the CEO of Adexa, wrote a good paper on this. He wrote, “with every iteration of planning, there are millions of variables to be considered, billions of versions of plans that can be produced, and thousands of variables which are constantly and dynamically changing.” Much of the data needed to properly update the planning model exists in execution systems. What Adexa is visualizing is having a self-correcting engine continuously scrutinize the data in these systems and then automatically update the parameters in the supply planning engine when warranted.
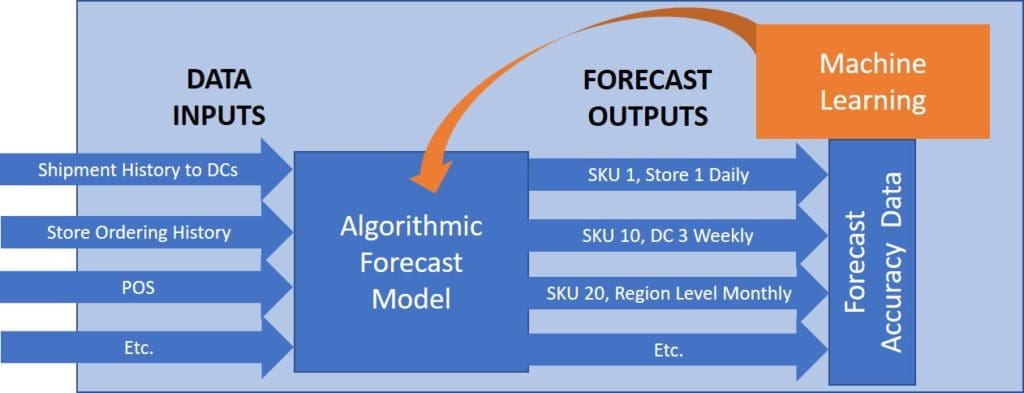
Architecturally, applying machine learning in supply planning is more difficult than its use in demand planning. In a demand management application, the system is continuously monitoring forecasting accuracy. That accuracy data in the system allows for the learning feedback loop. Further, demand planners, the people that use the outputs of the system, play a core role in making sure the data inputs stay clean and accurate.
In supply planning, the data comes from a different system or systems. Improving operations can be extraordinarily challenging if the data that holds the answers is scattered among different incompatible systems, formats and processes. And the people responsible for making sure the data put into various systems is accurate don’t use the system outputs; in short, they have less incentive for making sure inputs stay clean. This is a master data management problem.
A form of middleware/business intelligence must access up-to-date and clean data, analyze it, and then either automatically change the parameters in the supply planning application or alert a human that the changes need to be made.
These solutions do exist. I’m most familiar with the solution from OSIsoft, the PI System, which collects, analyzes, visualizes and shares large amounts of high-fidelity, time-series data from multiple sources to either people or systems.
But this means that to use machine learning in supply planning, you need not just the supply planning application, but middleware and master data management solutions. In this kind of situation, the integration, cultural, and, consequently, ROI issues become more difficult.
Leave a Reply