







Companies love benchmarking data. Its use helps “appropriately” reward managers and line level employees, set tactical improvement targets, and even drive strategic initiatives. Bad benchmarking data gives companies the illusion they are running their business professionally. It is often the opposite; bad benchmarking often leads to poor decisions. Robust benchmarking does exist but is relatively rare. For example, setting labor productivity goals in the warehouse based upon on time studies or predetermined time systems is robust. So is Chainalytics Freight Market Intelligence Consortium (FMiC) which provides for sound lane/rate freight benchmarking.
And Chainalytics has done it again. Their relatively new and less known, Demand Planning Intelligence Consortium (DPiC) provides yet another powerful benchmarking tool. DPiC is built on many of the same principles as FMiC. Chainalytics’ Jaime Reints – Director of DPiC – and Ben YoKell – Vice President of Integrated Planning, graciously gave me a very detailed briefing that allowed me to get into the weeds of what they are doing and how they are doing it. What follows are some highlights from that briefing.
Robust Benchmarking of Demand Forecasts
Here is the basic goal: If, for example, you were looking at a demand planning team that had achieved forecast accuracy of 79 percent for a certain set of products, is that good or bad?
What are the main steps Chainalytics took to get to sound and actionable analytics? First of all, companies must give to get. Their members have contributed over $72 billion in forecast data to the benchmarking exercise. Ms. Reints believes they will have $100 billion in data by the end of the year. Statistically, you need density to have a meaningful analysis.
Secondly, one needs to start with defined benchmark metrics. Different types of metrics are used as if they were measuring the same thing – Mean Absolute Percent Error (MAPE) measured in a monthly bucket will yield different results than a Weighted MAPE in a weekly measure of accuracy. But beyond these standard metrics, Chainalytics has some non-obvious metrics that I had never come across – and I’ve been in this game a long time – which yield quite interesting insights.
Chainalytics has not only defined the core metrics, they calculate these metrics for their members! They’ve mapped the demand master data in their member’s systems, pulled the data out, and made the calculations to ensure that the calculations are accurate. In the process of onboarding new members, they have often uncovered errors in the way companies were calculating their forecast accuracy. Thus, before members even receive benchmarking data, they may have already begun to gain value from this exercise.
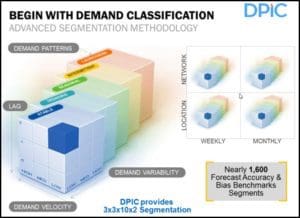
Thirdly, there needs to be mathematical rigor in the analysis. And the math needs to have a defendable point of view. Chainalytics’ perspective is that demand benchmarking should be based on an understanding of how hard it is for a company to plan their demand in the first place. Fast moving products that are never promoted and have no seasonality effects are far easier to forecast than extremely slow moving products that consequently have intermittent demand patterns.
Some groups of products may have a promotion that may lead to a doubling of demand; other products can have a promotion that can drive as much as a tenfold increase in demand. The latter is clearly harder to forecast than the former.
The consortium has classified every item along multiple dimensions – stability, trending, seasonality, intermittency, and products that are just being introduced or will soon be retired. This analysis is done at both the item level, and the item/location level. Here, “location” is defined as the company’s internal stocking location. This analysis is done twice a year.
At one point in our conversation Mr. YoKell said, “I remember in 2013 when we started looking at this concept, and we were shocked by the lack of genuine rigor in the few other approaches we found out there. At how non-standard and pseudo-scientific the data out there was. I was aghast at how casual it all was. There was nice window dressing, but no statistical strength.”
I’ve come across the same thing across a wide range of benchmarking tools. Robust benchmarking is still rare. DPiC is an exception.
Leave a Reply